[V8]使用VS Code调试V8代码

![[V8]使用VS Code调试V8代码](/content/images/size/w2000/2018/11/v8.svg)
最近在做一些v8的项目开发,其中需要调试一些代码,但是总是打印log的效率太低,所以研究了一下如何在vscode上调试v8代码.
- 使用vscode打开v8的源代码,在v8的目录下创建.vscode的目录,该目录是存放vscode的配置信息.
- 新建launch.json
{
"version": "0.2.0",
"configurations": [
{
"name": "v8 sample Debug",
"type": "cppdbg",
"request": "launch",
"targetArchitecture": "x64", //要debug肯定是桌面版本的
"program": "${workspaceRoot}/out/Debug/v8_hello_world",
"args": [], // Optional command line args
"preLaunchTask": "build_v8_hello_world", //这个是在debug之前做的任务,比如编译等,可以手动自己编译,不需要可以注释掉
"stopAtEntry": false,
"cwd": "${workspaceRoot}",
"environment": [{"name":"workspaceRoot","value":"${HOME}/v8/src"
}], //设置v8的环境变量,工作目录
"externalConsole": false //使用内置的console
}]
}
3.新建tasks.json (可选)
{
"showOutput": "always",
"echoCommand": true,
"tasks": [
{
"taskName": "build_v8_hello_world",
"command": "ninja -C out/Debug v8_hello_world", //编译sample代码
"isShellCommand": true,
"isTestCommand": true,
"problemMatcher": [
{
"owner": "cpp",
"fileLocation": ["relative", "${workspaceRoot}"],
"pattern": {
"regexp": "^../../(.*):(\\d+):(\\d+):\\s+(warning|\\w*\\s?error):\\s+(.*)$",
"file": 1, "line": 2, "column": 3, "severity": 4, "message": 5
}
},
{
"owner": "cpp",
"fileLocation": ["relative", "${workspaceRoot}"],
"pattern": {
"regexp": "^../../(.*?):(.*):\\s+(warning|\\w*\\s?error):\\s+(.*)$",
"file": 1, "severity": 3, "message": 4
}
}]
}]
}
-
这时可以看到在vscode的调试界面,已经可以看到我们在launch.json中配置的内容了.
-
配置完成之后,现在要配置gn的信息了.
gn --args='is_debug= true dcheck_always_on = true is_component_build = true enable_nacl = false v8_optimized_debug = false ' gen src/out/Debug
这里有2个点需要注意,一是is_debug= true,这个标记是否开启调试模式,二是v8_optimized_debug = false,这个标记代表是否对v8的代码在编译时优化,我们知道gcc编译时,有-O0,-O1,-O2,-O3这几档来优化代码,减少产生的体积.
1.-O0:
不优化.
2.-O1:
这两个命令的效果是一样的,目的都是在不影响编译速度的前提下,尽量采用一些优化算法降低代码大小和可执行代码的运行速度。并开启如下的优化选项:
-fauto-inc-dec
-fbranch-count-reg
-fcombine-stack-adjustments
-fcompare-elim
-fcprop-registers
-fdce
-fdefer-pop
-fdelayed-branch
-fdse
-fforward-propagate
-fguess-branch-probability
-fif-conversion2
-fif-conversion
-finline-functions-called-once
-fipa-pure-const
-fipa-profile
-fipa-reference
-fmerge-constants
-fmove-loop-invariants
-freorder-blocks
-fshrink-wrap
-fshrink-wrap-separate
-fsplit-wide-types
-fssa-backprop
-fssa-phiopt
-fstore-merging
-ftree-bit-ccp
-ftree-ccp
-ftree-ch
-ftree-coalesce-vars
-ftree-copy-prop
-ftree-dce
-ftree-dominator-opts
-ftree-dse
-ftree-forwprop
-ftree-fre
-ftree-phiprop
-ftree-sink
-ftree-slsr
-ftree-sra
-ftree-pta
-ftree-ter
-funit-at-a-time
- -O2
该优化选项会牺牲部分编译速度,除了执行-O1所执行的所有优化之外,还会采用几乎所有的目标配置支持的优化算法,用以提高目标代码的运行速度。
-fthread-jumps
-falign-functions -falign-jumps
-falign-loops -falign-labels
-fcaller-saves
-fcrossjumping
-fcse-follow-jumps -fcse-skip-blocks
-fdelete-null-pointer-checks
-fdevirtualize -fdevirtualize-speculatively
-fexpensive-optimizations
-fgcse -fgcse-lm
-fhoist-adjacent-loads
-finline-small-functions
-findirect-inlining
-fipa-cp
-fipa-cp-alignment
-fipa-bit-cp
-fipa-sra
-fipa-icf
-fisolate-erroneous-paths-dereference
-flra-remat
-foptimize-sibling-calls
-foptimize-strlen
-fpartial-inlining
-fpeephole2
-freorder-blocks-algorithm=stc
-freorder-blocks-and-partition -freorder-functions
-frerun-cse-after-loop
-fsched-interblock -fsched-spec
-fschedule-insns -fschedule-insns2
-fstrict-aliasing -fstrict-overflow
-ftree-builtin-call-dce
-ftree-switch-conversion -ftree-tail-merge
-fcode-hoisting
-ftree-pre
-ftree-vrp
-fipa-ra
- -O3
该选项除了执行-O2所有的优化选项之外,一般都是采取很多向量化算法,提高代码的并行执行程度,利用现代CPU中的流水线,Cache等。
-finline-functions // 采用一些启发式算法对函数进行内联
-funswitch-loops // 执行循环unswitch变换
-fpredictive-commoning //
-fgcse-after-reload //执行全局的共同子表达式消除
-ftree-loop-vectorize //
-ftree-loop-distribute-patterns
-fsplit-paths
-ftree-slp-vectorize
-fvect-cost-model
-ftree-partial-pre
-fpeel-loops
-fipa-cp-clone options
这个选项会提高执行代码的大小,当然会降低目标代码的执行时间。
- 现在配置都基本完成了,现在按下F5,进行调试,我们就可以看到如下的内容了.
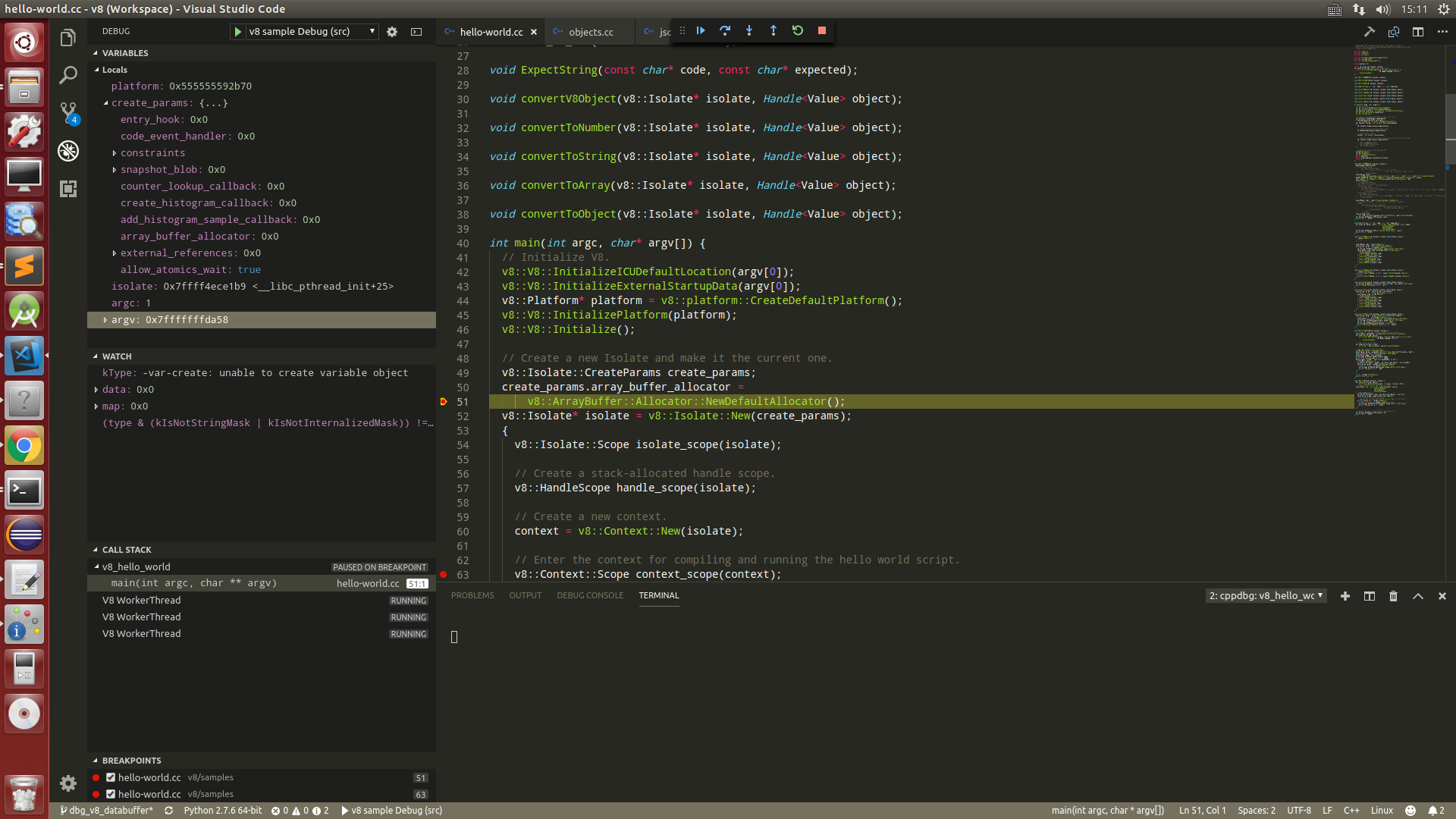
至此,调试工作正式开始